
What is the deal with Cat-Qubits?
A surprisingly new and alternative path to fault tolerant quantum computation is emerging. Fuelled by recent impressive results, “cat qubits” […]
A surprisingly new and alternative path to fault tolerant quantum computation is emerging. Fuelled by recent impressive results, “cat qubits” […]
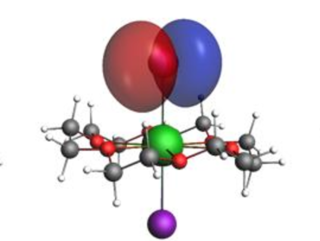
Quantum chemistry is one of the top most promising and one of the first applications for quantum computing. Most likely,

Quantum chemistry is one of the top most promising applications for quantum computing – due to the quantum nature of

I am delighted that the well-known German iX-magazine about professional computing has published my new article: As a 7-page cover-story

The realization of quantum RAM aka QRAM would be a game changer for the quantum industry. Very promising proposals almost

Regarding the importance of exponential quantum advantages, it is natural to ask how far the boundaries of known, superfast quantum

As quantum computing evolves the community focuses on the next steps towards fault tolerance. Recent estimates for the overhead of
Ever since Feynman‘s statement “Nature isn‘t classical dammit“ there exists the general agreement in the quantum computing community that fault
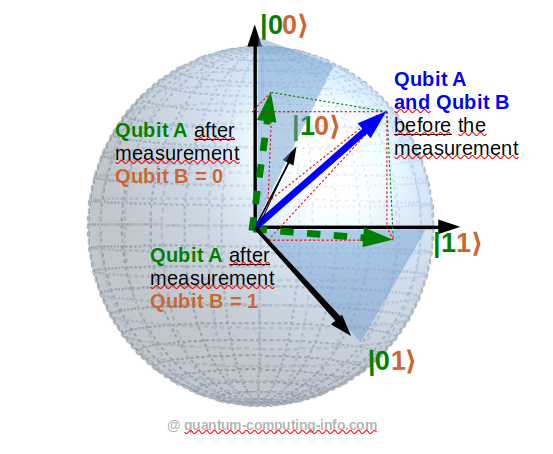
In case you want to explain some central aspects of quantum information theory to curious people (like to explain aspects

In August 2022 news has spread through the media, that a team of researchers from the Chinese Academy of Sciences