
The State of Quantum RAM: A new enlightening Investigation
The realization of quantum RAM aka QRAM would be a game changer for the quantum industry. Very promising proposals almost […]
The realization of quantum RAM aka QRAM would be a game changer for the quantum industry. Very promising proposals almost […]

Regarding the importance of exponential quantum advantages, it is natural to ask how far the boundaries of known, superfast quantum
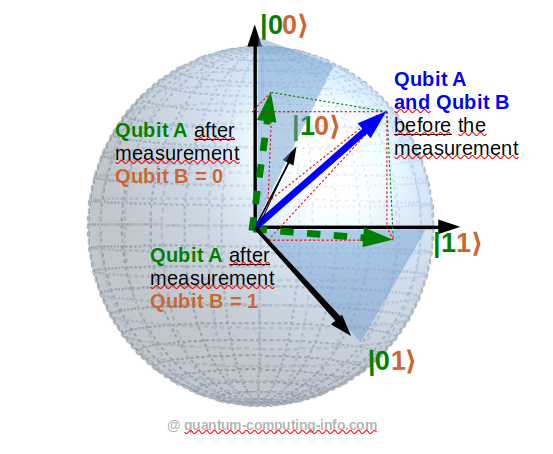
In case you want to explain some central aspects of quantum information theory to curious people (like to explain aspects